Intéressante coïncidence qui s’est déroulée en l’espace de deux petites minutes la semaine dernière… Voyez plutôt.
Sur le fil #eprdctn de Twitter, je découvre donc ce message d’un « designer/consultant » qui se définit comme gourou d’un outil commercialisé par un acteur très majeur, logiciel dont il ne saurait bien évidemment se passer.
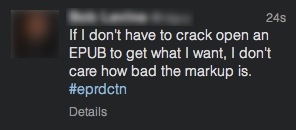
Traduisons le message…
Si je n’ai pas besoin d’ouvrir un fichier EPUB pour obtenir ce que je veux, je m’en fous si le balisage est mauvais.
Deux minutes plus tard, en survolant un test de liseuses dont je ne citerai pas la marque, je tombe sur ce message d’un lecteur dans les commentaires :

En brut pour soigner l’accessibilité, ça donne :
De toute façon, vu comme la plupart des ePub sont dégueulasses (même — et surtout ? — ceux issus de vendeurs), je reformate toujours mes livres dans Calibre avant de les envoyer (suppression de la marge avant chaque paragraphe, correction des alinéas, suppression de tous les styles imbriqués, uniformisation du texte, quand ça n’est pas refaire la table des matières ou autres…).
Vous voyez un lien de cause à effet ? Eh bien moi aussi. Et je ne vais pas m’étendre sur le sujet mais sachez que « la cause » (première capture) est en train de mettre un bordel — il n’y a pas d’autre mot — monstrueux dans l’écosystème.
Quelques jours plus tard, le « gourou » signe et persiste sur ce même fil de discussion (attention, la discussion commence tout en bas, il faut la remonter) :
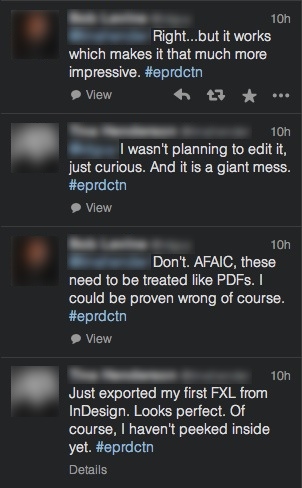
Traduisons cette discussion…
« Je viens d’exporter mon premier fixed-layout depuis InDesign. Ça rend parfaitement au visuel. Bien sûr, je ne me suis pas plongé dans le code généré.
— Ne t’y plonges pas. En ce qui me concerne le fixed-layout doit être traité comme le PDF. On pourrait me dire le contraire bien évidemment.
— Je ne prévoyais pas de le modifier, j’étais juste curieux. Et c’est un énorme bordel.
— Bien… mais ça fonctionne, ce qui rend l’export encore plus impressionnant. »
Et c’est ainsi que nous rendons l’écosystème toxique, les développeurs de solutions de lecture se pliant en 4 pour que les fichiers soient un minimum lisibles, créant des modifications à la volée (overrides) pour prendre en charge les exports dégueulasses des outils qui promettent monts et merveilles. Ce qui est réellement impressionnant, c’est de voir ces développeurs passer leur temps à rattraper le coup pour que l’écosystème ne s’effondre pas sous le poids des fichiers mal faits, sans broncher.
Creusons encore un peu : le temps que les développeurs passent à colmater les brèches pourrait bien peser sur le développement des solutions de lecture. Nous en arrivons donc à nous poser ce genre de question :
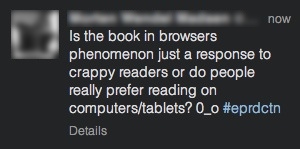
En français :
Est-ce que le phénomène de « livre dans le navigateur » est juste une réponse aux solutions de lecture pourries ou est-ce que les gens préfèrent réellement lire sur leur ordinateur/tablette ? O_o
Je pense personnellement que c’est la première alternative qui s’impose, les éditeurs et développeurs de livres numériques n’en pouvant plus d’attendre que la situation s’améliore — ça fait 3 ans qu’ils trépignent, ce qui correspond au lancement d’EPUB3. Résultat, ils commencent à se tourner vers les navigateurs.
Tout le monde le sait mais rien ne se passe vraiment du côté des apps de lecture…
Il y a bien évidemment plusieurs problématiques à prendre en compte pour l’expliquer (coûts notamment) mais il semble que le développement de ces applications est également freiné par la prise en charge « au moins pire » des fichiers de mauvaise qualité : les fondations que nous avons construites ne sont pas saines, l’écosystème technique n’est donc pas aussi solide qu’il devrait l’être et les les développeurs doivent prendre des précautions pour que le tout ne s’écroule pas — et sachez que cette observation ne vient pas de moi mais de plusieurs personnes bien renseignées.
Nous en profiterons donc pour rappeler au « gourou » que :
- le web a mis 10 ans pour le comprendre mais s’est finalement débarrassé des gens qui travaillaient comme lui ;
- l’édition finira par le considérer comme un incompétent doublé d’un irresponsable si, à force de tirer sur la corde avec d’autres, des pans de l’écosystème d’EPUB finissent par céder — et cela inclut les lecteurs ;
- l’édition se débarrassera de lui comme le web a pu le faire avec ses compères du web, l’Histoire se répète toujours.
Nous n’avons vraiment pas besoin de « gourous » qui se foutent de la qualité des livres numériques et encore moins de ceux qui le revendiquent.
Je vous laisse méditer là-dessus et là-dessus.
Symptomatique du one-button-solution. J’avais vu passer cet échange mais pas repéré la position professionnelle de cette personne sur le coup.
Le problème dans tout ça demeure la dépendance de la sphère éditoriale à Indesign. Je me demande comment les choses vont évoluer. S’oriente t’on vers une transition douce en faveur de la qualité, ou vers une saturation progressive de mauvaises pratiques qui risquent de mettre tout le monde par terre ?
Le web est sorti de cette phase, car il n’était pas vraiment envisageable qu’il fasse autrement. Ma grande peur c’est que la même chose ne se produise pas forcément pour le livre (numérique) qui est un écosystème plus restreint, avec des acteurs professionnels moins portés sur l’innovation.
Le scénario catastrophe serait que la dégradation continue et qu’Adobe sorte de sa manche un format (propriétaire) mi-reflow, mi-FXL, exportable directement depuis leur suite logiciel et lisible via RMDSK. Ma main à couper que beaucoup d’éditeurs se jetteraient dedans avec la promesse que ça règlerait tous leurs problèmes…
Plusieurs propos intéressants sur lesquels rebondir, merci 🙂
1. InDesign : on se rend compte en formation qu’une partie significative du problème vient de l’UI–UX. Par exemple, pourquoi le panneau de balisage d’exportation n’est pas affiché automatiquement lors de l’export EPUB ? Quasiment personne ne sait qu’il faut aller le chercher dans le menu du panneau des styles… Et ce n’est pas le seul problème d’UI–UX qui vient pourrir une grande partie des fichiers qui en sont exportés. Malheureusement.
2. À voir les spécifications « Multiple Renditions » — c’est un peu le format mi-reflow, mi-FXL que tu imagines — et « Region-based Navigation », j’ai peut-être davantage peur que toi. Ce sont des spécifications qui n’ont fait l’objet d’aucune approche UX, ce sont des spécifications qui ont été pensés par des techniciens et qui pourraient se montrer tellement complexes que nous deviendront ultra dépendant des outils proposés par… les boîtes qui embauchent certaines personnes qui ont participé à l’élaboration de ces specs — comme par hasard.
Sauf que ces spécifications ne règlent aucun de nos problèmes actuels ; on ne se préoccupe même plus du reflow alors que nous avons des besoins énormes pour la non-fiction (construire des relations entre les différents contenus — au-delà de la note de bas de page —, lier les contenus pour permettre d’y accéder et de les manipuler, etc.).
Donc, on complique encore un peu plus alors que ça galère déjà pour implémenter les specs de base et, en plus, on développe des specs pour faire des choses dont on sait que ça ne fonctionne pas, les approches choisies ayant très largement démontré leur échec sur l’expérience utilisateurs dans d’autres domaines…
3. J’ai quand même de l’espoir à voir le livre blanc EPUB–WEB, où il est marqué noir sur blanc que l’IDPF et le W3C essayent de répondre à la problématique du développement de l’expertise web chez les éditeurs : construire un lien solide qui permettra à ces éditeurs de travailler avec les gens du web et non plus avec les « gourous ».
4. une grosse partie du boulot chez les freelances anglophones consiste à corriger des fichiers qui ont été mal réalisés. Ça m’a frappé il y a quelques mois. Autrement dit, il vaudrait mieux que tout le monde comprenne que la mauvaise qualité finit toujours par se payer et que ça fait perdre beaucoup de temps et d’argent. Aujourd’hui, tu as des boîtes qui répondent à des appels d’offre en annonçant qu’il faudra de toute manière tout refaire dans 2 ans. Le jour où ces propositions seront disqualifiées d’office, on aura déjà fait un grand pas…
À lire la prose récente, je pourrais finir par me dire (et je serais sûrement pas le seul) : c’est infaisable de faire du Numérique !
Pourtant, malgré la jeunesse de l’export ePub FXL d’InDesign, je m’amuse depuis un mois et demi (professionnellement parlant) à concevoir des animations (et autres enrichissements) relativement complexes et originales en m’inspirant dans les grandes lignes de ce que Aquafadas, Twixl et autres proposent, à exporter en ePub FXL, à valider les fichiers (toujours OK !!) et à les tester sur IOS & Android, iBooks, ADE, Readium et Kobo reader…
Et … je ne rencontre aucun problème !!
Comble de l’ironie, je suis convaincu au final que la version « numérique » fortement enrichie (et donc fortement différente) déclinée de concert avec la version print (d’un livre) pourrait être facturée « 1 euro » ! (pour x raisons dont on pourrait reparler une autre fois.)
Y aurait-il quelque chose qui m’échappe ou ferait-on différemment les livres sur Tatooine ?
Yep, ce qui échappe en général, c’est ce qui se trouve dans le fichier et pas à l’écran : structure sémantique, CSS, accessibilité, bonnes pratiques, respect des spécifications revendeurs — par exemple, le FXL InDesign avec ses styles inline (dans dans les fichiers XHTML), il va à l’encontre des spécifications Kobo si on les regarde strictement, puisqu’elles demandent expressément de ne pas faire comme ça, les styles inline pouvant créer des gros soucis de rendu. C’est de toute manière une des pires choses à faire en HTML/CSS mais il semblerait que certains n’ont jamais discuté avec des mecs du web.
Le truc, c’est qu’on peut s’amuser — il vaut même mieux — mais nous avons des responsabilités étant donné que nous construisons collectivement les bases de tout l’écosystème en ce moment-même. Et là, l’écosystème tient parce que derrière, les développeurs de solutions de lecture (moteurs de rendu, apps, appareils, etc.) et parfois même les distributeurs sauvent le coup par rapport aux fichiers qui sont mal faits. Donc peu importe que ça passe correctement sur telle ou telle machine à un instant T, c’est juste que ces développeurs posent des rustines au fur et à mesure. Sauf qu’il va bien arriver un moment où ça va péter quelque part.
On en est quand même au point où certains développeurs ne veulent pas intégrer le support du FXL pour ne pas avoir à gérer tout ça, pour info…
Quant à la validation ePubCheck, je peux te faire un fichier complètement bogué, le plus dégueulasse possible et quand même te le faire passer sans aucun souci. ePubCheck ne vérifie pas tout et ce n’est de toute façon pas sa vocation pour le moment — même si j’ai entendu qu’il y avait une réflexion pour reporter d’autres avertissements et erreurs.
Derrière, ce qui se passe :
Je ne dis pas qu’il n’y a pas des fichiers très bien faits et pensés. Mais qu’on n’en vienne à oublier la base (structure sémantique, accessibilité, etc.), ça c’est faute pro à mon sens. OK pour utiliser des outils qui simplifient la vie, pas OK pour les utiliser aveuglément. À ce stade du livre numérique, on devrait choisir des solutions en regardant ce qu’elles sortent et privilégier celles qui se démerdent le mieux. Si on ne peut pas le faire, c’est grave parce que ça veut dire qu’il manque des compétences à tous les niveaux.
Pire encore, on l’a vu avec l’annonce de l’arrêt de DPS Single Edition, tu as beaucoup d’éditeurs qui se sont retrouvés avec une app refusée par Apple et Adobe ne savait même pas comment régler le problème. Ils ne pouvaient pas expliquer pourquoi ça ne passait pas la validation donc ne savaient pas du tout quoi faire. Il se passe quoi le jour où ça se passe pour le FXL ? Plus personne ne pourra en publier pendant des semaines ? Les éditeurs, paniqués, iront-ils voir ailleurs ? Demanderont-ils des comptes à leurs employés et leurs prestas ? Je serai content de ne pas dépendre d’un soft ou d’une extension le jour où ça arrivera. Mais en attendant, ça risque de bien faire mal à ceux qui se mettent en situation de dépendance par rapport à ces outils — et j’espère que cet événement fait office d’avertissement pour ceux qui se mettent dans cette situation…
Le numérique, c’est pas comme le papier, le résultat qu’on voit peut varier d’un moteur à l’autre mais peut aussi changer dans le temps. Et ben si la base est pas saine, on joue avec le feu et il ne faudra pas venir se plaindre le jour où ça ne fonctionnera plus comme il faut et que le fichier « s’écroulera » parce que ses fondations auront été réalisées n’importe comment — et je suis tout à fait d’accord qu’un humain peut faire pire qu’un logiciel, aucun souci avec ça.
Et encore, mon billet est « gentil » si on le compare avec celui de Baldur Bjarnason, qui est en fait le lien sur la dernière phrase de l’article, mais je le mets en brut pour que ce soit plus clair : Just say no to ebook CSS and JavaScript. C’était il y a un an, rien n’a changé, ça a même empiré donc je te laisse imaginer ce que les insultes dans l’article pourraient devenir aujourd’hui.
P.S. : Baldur, c’est un peu le mec qui écrit et dit tout haut ce que beaucoup pensent tout bas donc il convient de l’écouter attentivement. Y’a juste que comme il l’ouvre bien volontiers, ça ne plaît pas à certains… qui ont d’autres intérêts. Sauf qu’il tape très souvent là où il le faut et qu’on gagnerait franchement à en avoir des comme lui à l’IDPF.
Update : ai rajouté ce lien vers le blog de Matt Garrish, qui date de Juin 2014 et répercute donc des infos pour la première version de l’export mais qui démontre au moins que nous partons de loin.
Ce qu’il faut en retenir, cf. dernier commentaire :
Ce qui pourrait se traduire par :
La structure sémantique ne devrait pas être une amélioration proposée dans une MAJ, elle devrait être la base à atteindre avant de faire quoi que ce soit d’autre. On pourrait aussi rappeler leurs responsabilités aux développeurs d’outils, tiens.
Merci pour ces précisions, je travaille assez peu avec Indesign, je ne suis donc pas directement confronté à ces problèmes mais je garde un œil sur l’évolution de l’outil étant donné qu’il demeure (trop ?) incontournable dans le processus de production de la majorité des éditeurs.
Là c’est vraiment un point important. Pour moi, la nécessité d’utiliser du FXL sur un projet devrait être un signal d’alarme pour un éditeur, en dehors de certains cas particuliers. Si le livre ne peut pas passer en reflow, c’est probablement qu’il n’est pas adapté pour un usage numérique.
Je n’ai pas encore commencé à travailler sur de l’Epub 3, je ne suis donc pas encore parfaitement au point sur ses spécifications, mais l’Epub 2 propose déjà assez de fonctions pour assurer un résultat satisfaisant sur les trois quart de la production littéraire. Les publications complexes (tout le segment de la non-fiction) nécessitent un peu plus de travail et de réflexion, mais c’est parfaitement gérable en recomposable. Pourtant, même la gestion correcte des hyperliens ne semble pas aller de soi chez tout le monde (exemple classique, les notes de bas de page sans lien de retour vers l’appel dans le corps du texte).
Mais bon, les choses pourraient évoluer dans le bon sens grâce au militantisme de certains 😉
Tu as de la chance 😉
On manipule beaucoup de notre côté parce qu’il n’y a quasiment que ça en fichier source, donc on a dû rapidement créer un parser maison pour corriger toutes les merdes qu’ID t’exporte et nettoyer le balisage XHTML. Il va sans dire que la CSS générée automatiquement va directement à la poubelle.
C’est un peu embêtant parce que c’est quand même une perte de temps et, surtout, il y a beaucoup de choses que les développeurs du logiciel auraient dû prévoir pour l’export et pu intégrer avec des scripts (certains scripts ID réalisés par des développeurs de livres numériques existent d’ailleurs déjà et ne sont plus qu’à intégrer).
Et c’est pas comme s’il y avait assez d’utilisateurs pour leur pointer certaines choses mais ils ont d’autres priorités que d’améliorer l’export pour le rendre potable — ajouter des fonctionnalités à l’arrache, de partout, et pourrir encore un peu plus la sortie, par exemple. Mais bon, qui sont ces utilisateurs spécialistes pour oser leur dire quoi que ce soit, hein ? (cf. l’article « Indesign : 15 ans, l’âge bête » chez Macg.)
P.S. : je suis également bien placé pour savoir que des éditeurs développent ou font développer des CMS qui importent du InDesign pour éviter d’avoir à composer avec l’export intégré… Là, les mecs de chez Adobe devraient quand même commencer à se poser des questions, parce qu’on dépense de l’argent pour ne pas avoir à s’en servir pour le numérique.